werkzeug —— URL Routing
当wsgi应用涉及到多URL或者多视图函数时,我们就需要一个分发器。分发器的作用就是根据请求的url路径PATH_INFO找到相对应的视图函数,并返回一个响应。一个简单的做法就是在PATH_INFO上使用正则表达式,然后找到注册的回调函数。werkzeug就是这么做的,不过提供更强大的功能。
下面就是一个使用werkzeug.routing简单的例子。
from werkzeug.routing import Map, Rule, NotFound, RequestRedirect
url_map = Map([
Rule('/', endpoint='blog/index'),
Rule('/<int:year>/', endpoint='blog/archive'),
Rule('/<int:year>/<int:month>/', endpoint='blog/archive'),
Rule('/about', endpoint='blog/about_me')
])
def application(environ, start_response):
urls = url_map.bind_to_environ(environ)
try:
endpoint, args = urls.match()
except HTTPException, e:
return e(environ, start_response)
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Rule points to %r with arguments %r' % (endpoint, args)]
Map
首先,我们创建了一个Map对象url_map,然后我们传递一组Rule对象到url_map当中。
一个Map对象存储一组URL规则(这些规则通过Rule对象表示),和一些配置参数。这个类中还实现了几个重要的方法:
- add
python
def add(self, rulefactory):
for rule in rulefactory.get_rules(self):
rule.bind(self)
self._rules.append(rule)
self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule)
self._remap = True
这个方法用于相Map对象添加Rule对象(保存在_rules属性中),并绑定Rule对象(这个过程由Rule.bind()方法实现,这个方法将Rule对象绑定到对象,并创建该对象的正则表达式,并保存在_regex属性中),此外还更新了map的_rules_by_endpoint属性。
_rules_by_endpoint从名字可以猜出这个是用来保存endpoint到Rule对象的映射:
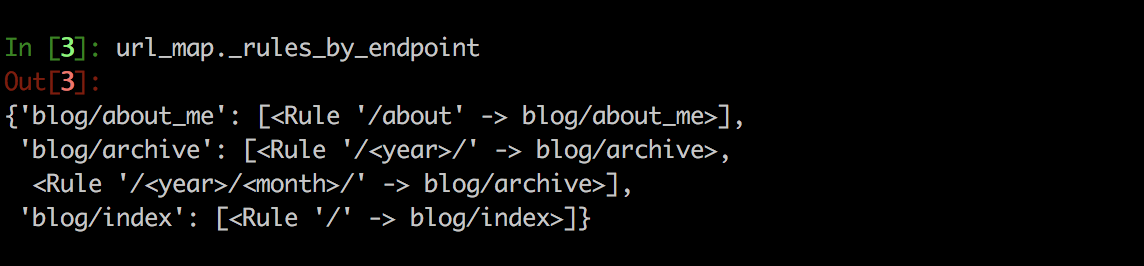
- bind
python
def bind(self, server_name, script_name=None, subdomain=None, url_scheme='http', default_method='GET', path_info=None, query_args=None):
# ... ...
return MapAdapter(self, server_name, script_name, subdomain, url_scheme, path_info, default_method, query_args)
这个方法主要用于生成一个MapAdapter对象,并把一些自身和一些请求信息传递给
adapter对象。
bind_to_environ
同bind,不过请求信息是通过wsgi环境变量传递。
Rule
每个Rule对象,有两个非常重要的属性string和endpoint,我们在实例化一个Rule对象时需要提供这两个参数:
- string: string是一个字符串,表示一个含有占位符
<converter(arguments):name>的url路径 - Endpoint:enpoint可以是任何数据对象,它的作用就是用来标识一个视图函数,至于endpoint和视图函数之间如何映射,werkzeug并没有约束我们,我们可以随心所欲。
Rule对象绑定到Map对象时,会创建该对象的正则表达式,并保存在_regex属性中:
def bind(self, map, rebind=False):
# ......
self.map = map
self.compile()
# ......
def compile(self):
"""Compiles the regular expression and stores it."""
assert self.map is not None, 'rule not bound'
if self.map.host_matching:
domain_rule = self.host or ''
else:
domain_rule = self.subdomain or ''
self._trace = []
self._converters = {}
self._weights = []
regex_parts = []
def _build_regex(rule):
for converter, arguments, variable in parse_rule(rule):
if converter is None:
regex_parts.append(re.escape(variable))
self._trace.append((False, variable))
for part in variable.split('/'):
if part:
self._weights.append((0, -len(part)))
else:
if arguments:
c_args, c_kwargs = parse_converter_args(arguments)
else:
c_args = ()
c_kwargs = {}
convobj = self.get_converter(
variable, converter, c_args, c_kwargs)
regex_parts.append('(?P<%s>%s)' % (variable, convobj.regex))
self._converters[variable] = convobj
self._trace.append((True, variable))
self._weights.append((1, convobj.weight))
self.arguments.add(str(variable))
_build_regex(domain_rule)
regex_parts.append('\\|')
self._trace.append((False, '|'))
_build_regex(self.is_leaf and self.rule or self.rule.rstrip('/'))
if not self.is_leaf:
self._trace.append((False, '/'))
if self.build_only:
return
regex = r'^%s%s$' % (
u''.join(regex_parts),
(not self.is_leaf or not self.strict_slashes) and
'(?<!/)(?P<__suffix__>/?)' or ''
)
self._regex = re.compile(regex, re.UNICODE)
MapAdapter
在wsgi应用中,我们把当前请求绑定到url_map中,得到一个MapAdapter对象urls。这个urls对象可以通过MapAdapter.match()方法来匹配当前请求。正常情况下,该方法会返回一个元组(endpoint, args) ,endpoint就是当前请求对应的端点,args就是相应的参数。
最后,我们直接把(endpoint, args)返回给客户端。实际运用中,我们会根据endpoint获取不同的视图函数,在视图函数中生成相应的http响应。
将一条URL规则的实例Rule添加进Map实例的时候,会为这个Rule生成一个正则表达式的属性_regex。MapAdapter.match()实际上会将请求中的url和每一条URL规则的正则表达式进行匹配。如果匹配成功,则会返回endpoint和一些参数。具体实现见下:
def match(self, path_info=None, method=None, return_rule=False,
query_args=None):
self.map.update()
if path_info is None:
path_info = self.path_info
else:
path_info = to_unicode(path_info, self.map.charset)
if query_args is None:
query_args = self.query_args
method = (method or self.default_method).upper()
path = u'%s|%s' % (
self.map.host_matching and self.server_name or self.subdomain,
path_info and '/%s' % path_info.lstrip('/')
)
have_match_for = set()
for rule in self.map._rules:
try:
rv = rule.match(path, method)
except RequestSlash:
raise RequestRedirect(self.make_redirect_url(
url_quote(path_info, self.map.charset,
safe='/:|+') + '/', query_args))
except RequestAliasRedirect as e:
raise RequestRedirect(self.make_alias_redirect_url(
path, rule.endpoint, e.matched_values, method, query_args))
if rv is None:
continue
if rule.methods is not None and method not in rule.methods:
have_match_for.update(rule.methods)
continue
if self.map.redirect_defaults:
redirect_url = self.get_default_redirect(rule, method, rv,
query_args)
if redirect_url is not None:
raise RequestRedirect(redirect_url)
if rule.redirect_to is not None:
if isinstance(rule.redirect_to, string_types):
def _handle_match(match):
value = rv[match.group(1)]
return rule._converters[match.group(1)].to_url(value)
redirect_url = _simple_rule_re.sub(_handle_match,
rule.redirect_to)
else:
redirect_url = rule.redirect_to(self, **rv)
raise RequestRedirect(str(url_join('%s://%s%s%s' % (
self.url_scheme or 'http',
self.subdomain and self.subdomain + '.' or '',
self.server_name,
self.script_name
), redirect_url)))
if return_rule:
return rule, rv
else:
return rule.endpoint, rv
if have_match_for:
raise MethodNotAllowed(valid_methods=list(have_match_for))
raise NotFound()
The end.